Standard Workflow with Mach Try Perf
This page is a guide for the standard workflow when working with ./mach try perf. It contains information for how you can make the most of this tool to enhance your development experience when working on performance.
Starting off with Mach Try Perf
In Mach Try Perf, there’s information about the purpose of tool along with and overview of the features. Here we’ll explain how to start working with it.
When mach try perf is run, the exact same interface as seen with ./mach try fuzzy will be shown, and everything works in the same way. However, instead of individual tasks, categories of tasks are displayed. To find more information what a particular category, or a selection of categories, will run on try, add the --no-push option to output a JSON file in your command console with all the selected tasks. Follow bug 1826190 for improvements to this.
Note
Some categories, like Benchmarks desktop, and Benchmark desktop firefox, will only produce different sets of tasks if another option such as --chrome or --safari is passed. As those kinds of flags are added, the Benchmarks desktop category will contain increasingly more tasks to prevent the need for finding, and selecting multiple subcategories. The tool is restrictive in what can be run by default, as generally, the other browsers aren’t needed in a standard workflow.
After selecting some relevant categories, and pressing enter in the interface, two pushes will start. The first push that happens is the new try run. It contains any patches that may have been made locally. After that, a base try run is produced which uses the mozilla-central those patches are based on. These two are then used to produce a Compare View link in the command console that can be used to quickly see the performance differences between the base, and new tests. Note that these two pushes can take some time, and there’s some work in progress to reduce this wait time here.
CompareView
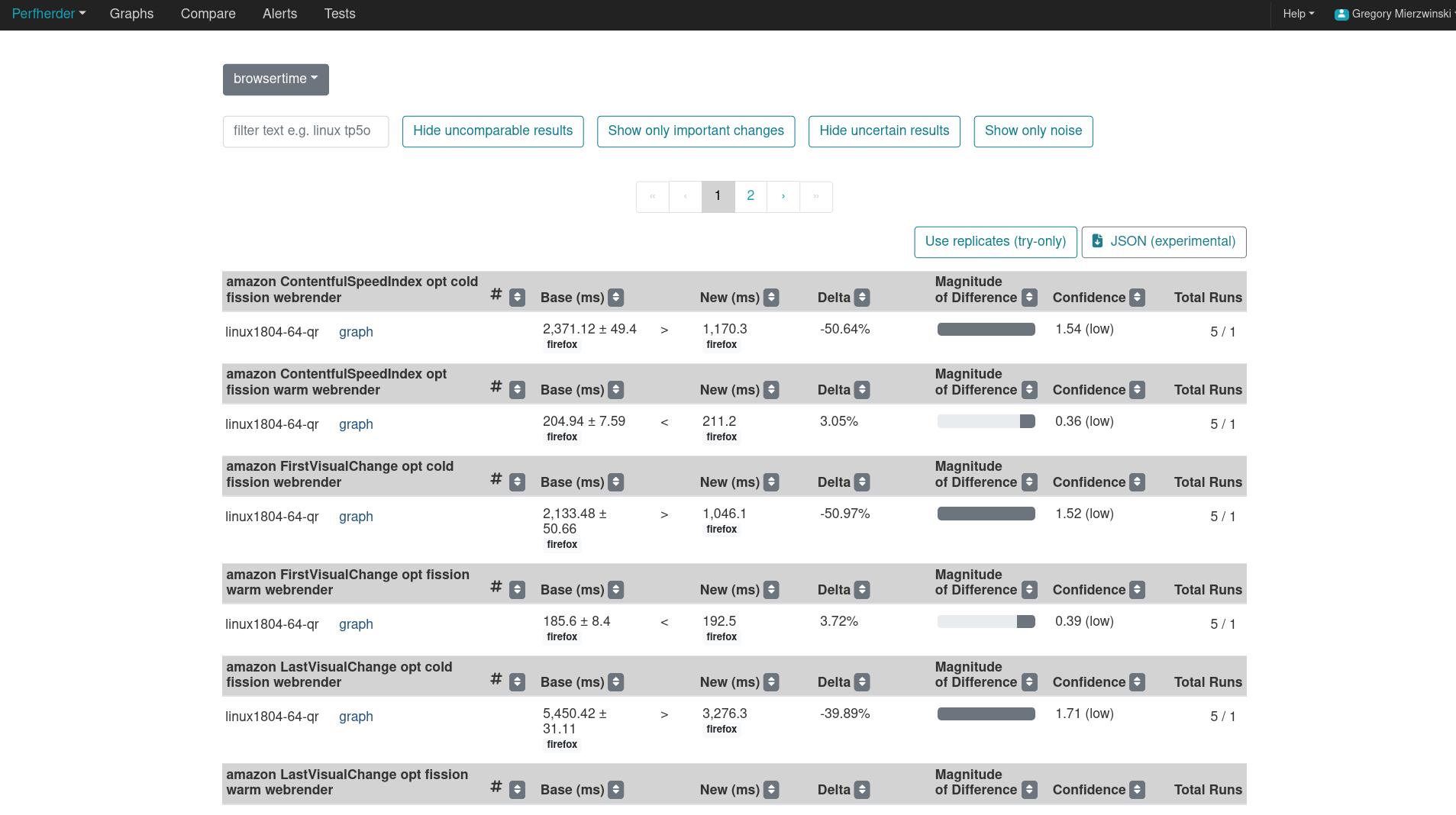
The CompareView provides a comparison of how the new revisions/patches change the performance of the browser versus the base mozilla-central revision. The image below shows the CompareView comparing two try commits to each other. If it doesn’t look like there’s enough data, hover over the table rows to reveal the “refresh”-like buttons (at the right-end next to the total runs) that are used to retrigger the tests. The revision links at the top of this page can be used to navigate to the individual try runs.
Note
The retrigger button in the CompareView is the simplest way to retrigger/rebuild tests on the base build. The base build that the try runs are produced on are cached locally to prevent wasting CI resources, however, this also means the --rebuild X option will only apply to the first try run made on a base revision. This cache can be cleared with --clear-cache.
Some more information on this tool can be found here.
Understanding the Results
In the image above, the base, and new columns show the average value across all tests. You can navigate to the try runs to retrigger the tests, or use the “refresh”-like button mentioned above (only visible while logged in). Hovering over the values in these columns will show you the spread of the data along with the standard deviation in percentage form. The number of data points used here can also be changed by clicking the Use replicates button at the top-right of the table (only for try pushes). It causes the comparison to use the trials/replicates data from the perfherder data instead of the summary values. Only 1 summary value is generated per task, whereas there can be multiple replicates generated per task. Here’s an example of where this data comes from in the PERFHERDER_DATA JSON (output in the performance task logs, or as perfherder-data.json file):
... # This type of data can be found in any PERFHERDER_DATA output
"subtests": [
{
"alertThreshold": 2.0,
"lowerIsBetter": true,
"name": "Charts-chartjs/Draw opaque scatter/Async",
"replicates": [ # These are the trials/replicates (multiple per task)
1.74,
1.36,
1.16,
1.62,
1.42,
1.28,
1.12,
1.4,
1.26,
1.44,
1.22,
3.32
],
"unit": "ms",
"value": 1.542 # This is the summary value of those replicates (only 1 per task)
},
...
The delta column shows the difference between the two revisions’ average in percentage. A negative value here means that the associated metric has decreased, and vice versa for positive values.
The Magnitude of change gives a visual indication of how large the change is, and the Confidence column shows the T-test value that the comparison produced. Higher values here indicate a higher degree of certainty over the differences.
The confidence, and base/new values are the main columns needed to understand the results. These show if the difference is something we’re confident in, and provides an absolute measurement of the difference. Retriggering tests will increase the number of data points available for comparisons, and produce a higher confidence in the differences measured. It’s also possible for retriggers to decrease the statistical significance of a change if it has a lot of variance.
The graphs link navigates to the Graphs View that can be used to visualize the data points, and navigate directly to each individual job. See [Graphs View] below for more information on this tool.
After looking over the results, and confirming that a patch either fixes a performance issue, or is confirmed to not cause performance issues, this concludes the standard workflow for ./mach try perf.
For any additional questions, please reach out to us in the #perftest channel on matrix.
Additional Information
Debugging an Alert
To debug an alert in CI, use ./mach try perf --alert <ALERT-NUMBER> to run the tests that alerted. After running the command, the standard workflow above still applies. See Running Alert Tests for more information on this.
Graphs View
The Graphs View will be used a lot when looking through the metrics in the Compare View. It can be used to see how the data spread looks if the tooltip hover in the Compare View is not enough. More information on it can be found here.
Perfherder
Perfherder is a performance monitoring tool that takes data points from CI log files and graphs them over time. It’s primary purpose is to find, and alert on changes that were detected, but it’s often used for simple manual monitoring as well.
The Graphs View, Alerts View, and Compare View, are all components of Perfherder. More information on this system can be found here.